この記事は古川研究室 Advent Calendar13 日目の記事です。 本記事は古川研究室の学生が学習の一環として書いたものです。内容が曖昧であったり表現が多少異なったりする場合があります。
本記事では、PCA こと主成分分析について理解した**”い”**をコンセプトに記事を書きました。
はじめに
まず PCA についてざっくりと書きます。
主成分分析とは、多次元の次元を下げる教習なし学習のことです。多次元データを人間が見やすいように 2 次元や 3 次元に落とし込むといったことを行います。低次元空間へ落とし込むとき、データの情報をできるだけ損なわないように、つまりデータの情報を最も含むように(分散値が大きくなるよう)にして落とし込みます。
何が嬉しいのか
では次元削減することで何が嬉しいのでしょうか?
例えば、ワインの成分には水、エタノール、有機酸、糖、グリセリン、アミノ酸、核酸、タンニン、炭酸ガスがあり 9 次元データになります。これらのデータにワインの評価を含めて 10 次元データを考えてみましょう。関係性を図やグラフなどで可視化することで"どういう成分比のときに評価値が高いのか"といったことを把握したいですが、我々人間には 4 次元以上の次元はわかりにくいです。そこで、PCA で我々人間が見やすい 2 次元、3 次元に次元を落とそうとして PCA を使うわけです。
主成分分析
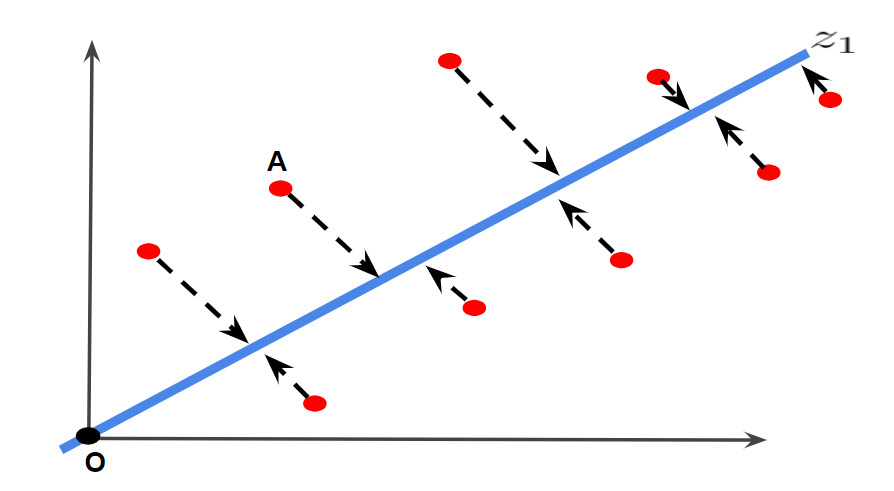
主成分分析では、データの情報を主成分軸という軸に情報を落とし込みます。3 次元に落とし込むなら 3 本の主成分軸、2 次元に落とし込むなら 2 本の主成分軸です。 注意してほしいことは、”空間を平面に"、"平面を直線に"落とし込んでいるのではなく、高次元から低次元への射影を行っているのです。
下図はイメージ図です。赤点のデータ点を 1 本の主成分軸に落とし込んでいます。
前処理
PCA の前処理として中心化というのがあります。中心化ではデータの値から、それらの平均値を引くことで平均 0 にすることです。これにより、データは原点を中心に分布します。
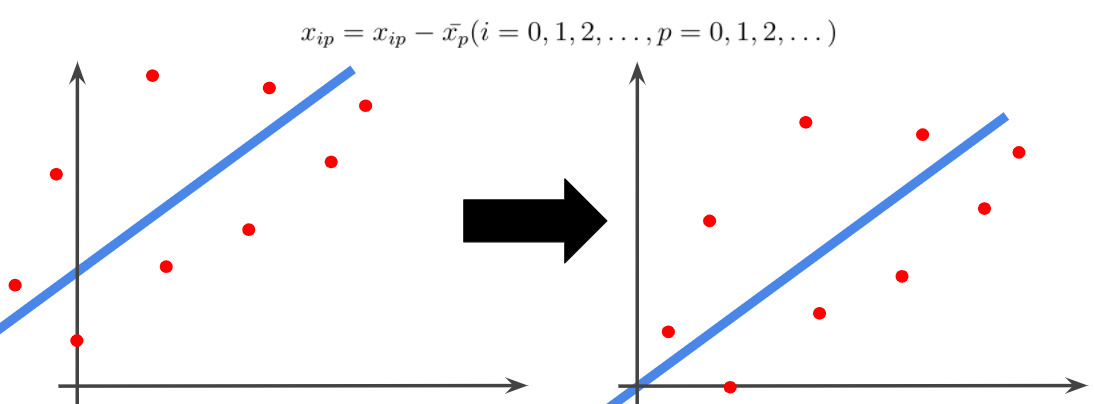
中心化する理由としては後述します。
どのようにしてやるのか
主成分分析では、情報をできるだけ損なわずにデータを射影します。裏を返せば得られる情報量が最大になればいいということです。したがって、次元削減して得られたデータの分散が最大になればいいということです。これを図を用いて考えてみます。ここで 9 つのデータの 1 つのデータ A に着目します。データを第 1 主成分で表す場合、の情報損失量は主成分軸に対して垂線を引いたです。
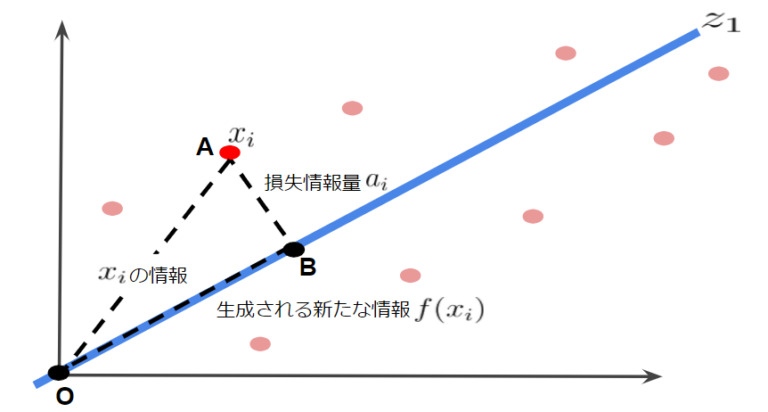
ここで、ピタゴラスの定理からの関係が成り立ちます。このとき、データA の情報量はで、得られる新たな情報量がになり主成分得点と言います。 したがって、9 点のデータに対して以下の関係性が成り立ちます。
”元情報量の 2 乗和=新たな情報量の 2 乗和+損失情報量の 2 乗和” この関係性からわかりますが、損失情報量を最小にすると、新たな情報量が最大になるのがわかります。
この考えは多変数の場合も同じです。したがって、
主成分分析とは変数をできるだけ元々の情報量を損なわないように、N 個の主成分に変換する手法のことです。つまり、P 次元から N 次元へ縮小
が第 1 主成分、が第 2 主成分、が第 n 主成分と言います。
主成分分析では、損失情報量を最小にすると、新たに得られる情報量が最大になります。この特性を利用して新たな情報量を最大化する最適化問題として扱うことができます。
この subject to は制約条件です。は主成分軸に対してに正規直交基底の役割を持たしています。
式を変形していきます。
\begin{equation*}\begin{split}\frac{1}{N}\sum_{i=1}^N(x_iw_{ip})^2= \frac{1}{N}\sum_{i=1}^N(x_iw_{ip})^T(x_iw_{ip})=\frac{1}{N}\sum_{i=1}^{N}w_{ip}^{T}x_{i}^Tx_{i}w_{ip}=\frac{1}{N}w^T\sum_{i=1}^N(x_i^Tx_i)w=w^TX^TXw\end{split}\end{equation*}
この式のはの行列であり、それぞれの要素はです。したがって、は分散・共分散行列になります。
ここで主成分分析の最適化問題を行列として表現します。
[st-mybox title="主成分分析の最適化問題" fontawesome="" color="#757575" bordercolor="#f3f3f3" bgcolor="#f3f3f3" borderwidth="0" borderradius="5" titleweight="bold" fontsize="" myclass="st-mybox-class" margin="25px 0 25px 0"]
は学習データの分散・共分散行列
上記の式において制約条件がない場合を考えると、明らかに解はであることがわかります。 制約条件の付いた最適化問題を解く手法としてラグランジュの未定乗数法があります。本記事ではラグランジュの未定乗数法を用います。
ラグランジュの未定乗数法
ラグランジュの未定乗数法自体については別記事を参考にしてください。
まず、最適化問題からラグランジュ関数の作成をします。
変数について偏微分すると
は分散・共分散行列であり対称行列なのでが成り立つ。したがって次の式が成り立つ。
この微分式の例は以下です。
\begin{equation*}\begin{split}\frac{\partial (w^TXw)}{\partial w}=\begin{pmatrix}\frac{\partial (w^TXw)}{\partial w_1}\ \\ \frac{\partial (w^TXw)}{\partial w_2}\end{pmatrix}=\begin{pmatrix}2w_1x_{11}+w_2x_{21}+w_2x_{12}\\ w_1x_{21}+w_1x_{12}+2w_{2}x_{22}\end{pmatrix}=\begin{pmatrix}x_{11}+x_{11} & x_{12}+x_{21} \\ x_{21}+x_{12} & x_{22}+x_{22} \end{pmatrix}\begin{pmatrix}w_{1} \\ w_{2}\end{pmatrix}=(X+X^T)w\end{split}\end{equation*}
変数について偏微分すると
これら、から主成分分析の最適化問題はラグランジュ未定乗数を固有値、ベクトルを固有ベクトルとした分散・共分散行列の固有値問題ということがわかる。
したがって、分散・共分散行列の固有値問題を解くことで最大となる固有値を求め、それに対応する固有ベクトルを求めることで主成分軸が得られる。
以上のことを踏まえると PCA のアルゴリズムは学習データが与えられたとき次のようになる。
PCA のアルゴリズム
①により中心化を行う
② 分散・共分散行列を解く
③ 下記の固有値問題を解く
④ 得られる固有値をそれぞれとする。
⑤ それぞれの固有値に対応する固有ベクトルを主成分軸の正規直交基底とし、縮小したい次元(2 次元なら 2 個)分を選択する。このとき、を順に第1主成分、第2主成分,,,となる。
⑥ 選択した固有ベクトルの行列の行列を作成し、学習データを低次元空間へ写像したときの主成分得点を算出する。