本記事は、Kaggle で最も有名なタイタニックのテーマに対して、CSV ファイルの取得から実際にスコアが出るところまでを行いたいと思います。
kaggle の登録や、kaggle とは何かについては別記事を参考にしてください
CSV 取得からスコア算出までのざっくりとした流れ
本記事ではスコア算出までの流れとして、以下の順で進めていきたいと思います。
- CSV ファイルからデータの取得
- データの可視化
- データの加工
- 相互情報量と相関係数
- 特徴量エンジニアリング
- モデルの決定
- 学習
- 学習結果を提出
1. CSV ファイルからデータの取得
Kaggle 上から CSV ファイルをローカルに落とし、それらを pandas を用いて変数 df_train と df_test へ代入します。
データの中身を上位5件だけ出力してみます。
df_train = pd.read_csv("train.csv") df_test = pd.read_csv("test.csv") print(df_train.head(5))
結果は次のようになります。
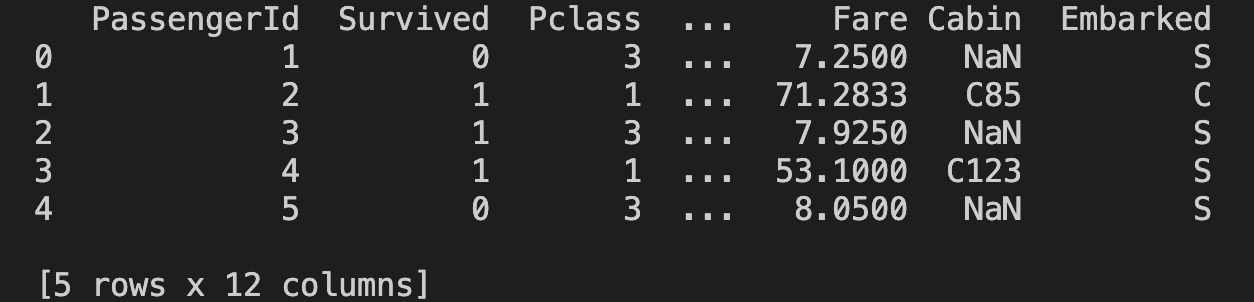
2. データの可視化
データ間の関係性を見るために、データの可視化を行っていきます。
可視化結果は、特徴量エンジニアリングやデータの加工のための大事な情報となります。
データ数と型の確認
まず、データ数と型を確認していきます。
df_train = pd.read_csv("../train.csv") df_test =pd.read_csv('../test.csv') print(df_train.info()) print(df_test.info())
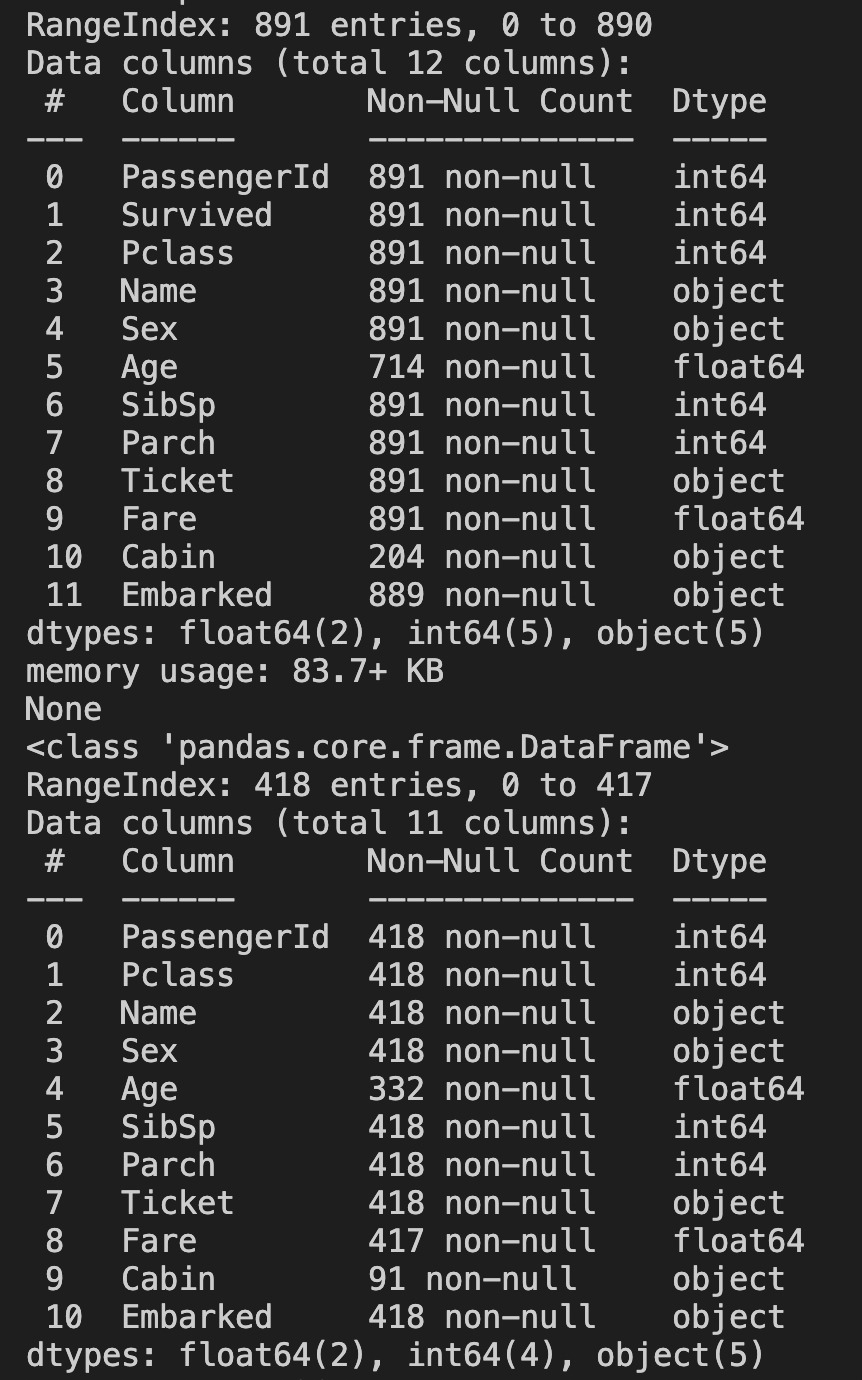
Object 型が何個かあるのがわかります。Object 型は学習できないので加工する必要があります。少なくとも 5 つのカラムについては消すか加工する必要がありそうです。
訓練データは 891 レコードと 12 カラムあるのがわかります。 テストデータは 417 レコードと 11 カラムあるのがわかります。
棒グラフによる可視化
seaborn の barplot を用いて Survived との関係を可視化していきます。 Survived はデータが 0 か 1 で表わされます。0 が死亡で 1 が生存になります。
この Survived に対して、任意のカラムに対してどれくらい生き残っているかを見ていきたいと思います。 例えば、Sex ならば、男性と女性で生存割合はどれくらい違うのかなどです。
一個一個のカラムで確認するのが面倒なので、for 文で一気にプロットしてまとめて確認したいと思います。 ここで棒グラフでプロットするときに注意なのは、データの種類が多い場合です。 横軸のカラムのデータの種類が多いと、比率なんてわかったもんじゃありません。
例えば、Age と Survived の関係を可視化すると次のようになります。 Age のデータの種類(年齢の違い)が多すぎて、何がなんなのかわかりません。
そのため、データの種類の少ないと思われる Pclass、Sex、Embarked、Parch、SibSip を一気に可視化したいと思います。
fig, axes = plt.subplots(3, 2, figsize=(16, 12)) axes = axes.ravel() column = ['Pclass', 'Sex', 'Embarked', 'Parch', 'SibSp'] for col, ax in zip(column, axes): sns.countplot(x=col, data = df_train, hue = 'Survived', ax=ax) plt.subplots_adjust(wspace=0.4, hspace=0.6) #グラフ間の余白を設定 plt.show()
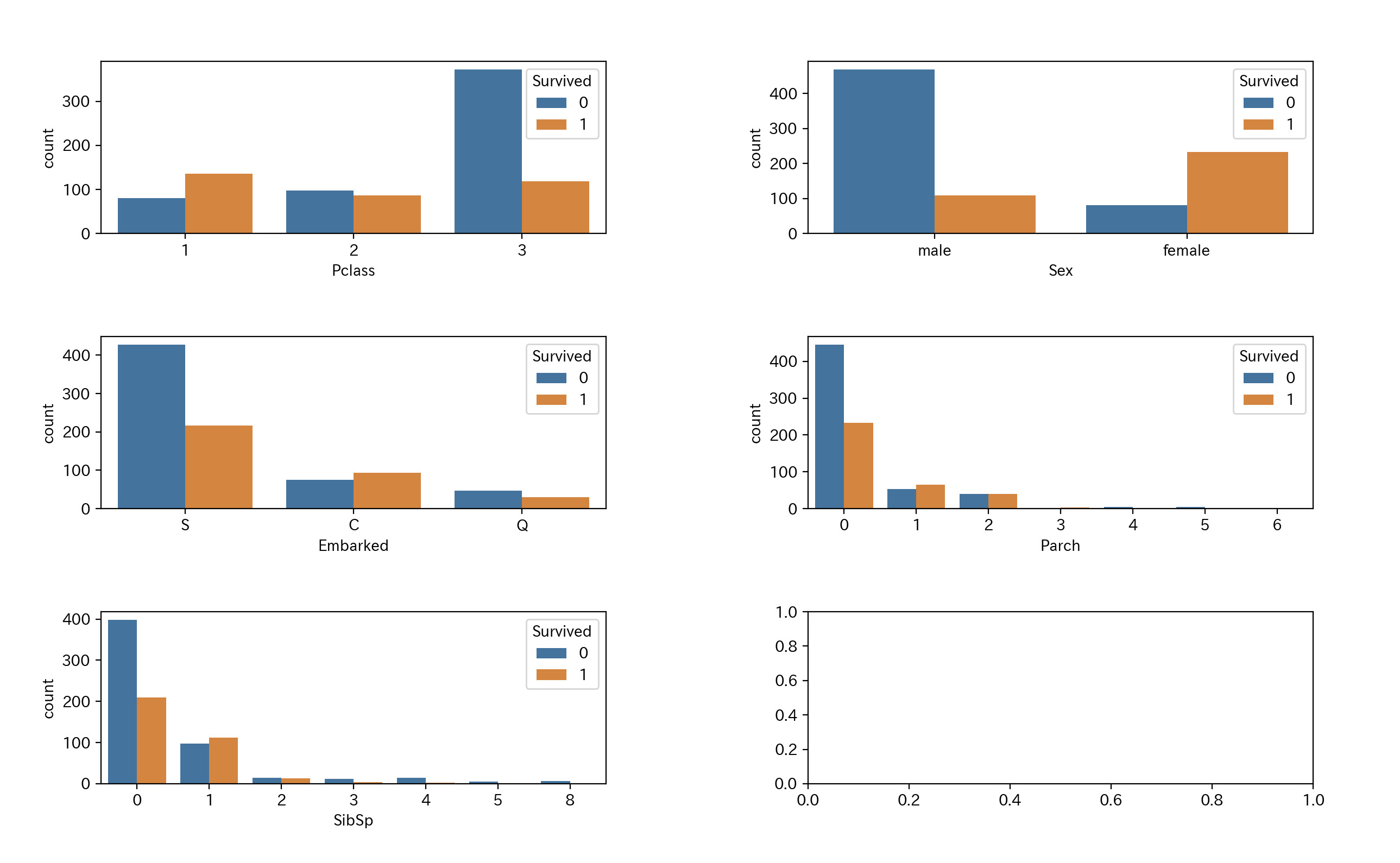
それぞれのカラムの意味をまとめておきます。
- Pclass – チケットクラス
- Sex – 性別(male=男性、female =女性)
- Embarked – 出港地(タイタニックへ乗った港)
- Parch – タイタニックに同乗している親/子供の数
- SibSp – タイタニックに同乗している兄弟/配偶者の数
得られた結果から次のことがわかりました。
| 結果 | 内容 |
|---|---|
| Pclass による結果 | お金がある人間であるほど生存率が高いです。お金..... |
| Sex による結果 | 女性の生存率が高いです。これは予想できますね。 |
| Embarked による結果 | C という港から乗船した人は生存率が高い。C はお金持ちが多かったのかな |
| Parch による結果 | 同乗している身内が多い人は生存率が低いです。共に船に残ったということですかね。 |
| SibSp による結果 | これも Parch と似た結果になっています。 |
ヒストグラムによる可視化
ヒストグラムは小数点レベルのデータを可視化させるときに役立ちます。 タイタニックでは float64 である Age と Fare が対象になります。
乗船した人で年齢割合、運賃の割合はどれくらいなのかを全体的に見て、その中で生存、死亡している人の割合を見ていきたいと思います。
column = ['Age', 'Fare'] fig = plt.figure(figsize=(16, 12)) gs = GridSpec(nrows=2, ncols=2, height_ratios=[1, 1]) axes = [fig.add_subplot(gs[0, 0]), fig.add_subplot(gs[0, 1]), fig.add_subplot(gs[1, 0]), fig.add_subplot(gs[1, 1]),] # 全体 sns.distplot(df_train["Age"], kde=True, color='black', ax=axes[0]) sns.distplot(df_train["Fare"], kde=True, color='black', ax=axes[1]) # 生存か死亡か sns.distplot(df_train[df_train["Survived"]==1]["Age"], kde=True, label=0, ax=axes[2]) sns.distplot(df_train[df_train["Survived"]==0]["Age"], kde=True, label=1, ax=axes[2]) sns.distplot(df_train[df_train["Survived"]==1]["Fare"], kde=True, label=0, ax=axes[3]) sns.distplot(df_train[df_train["Survived"]==0]["Fare"], kde=True, label=1, ax=axes[3]) plt.legend() plt.subplots_adjust(wspace=0.2, hspace=0.2) plt.show()
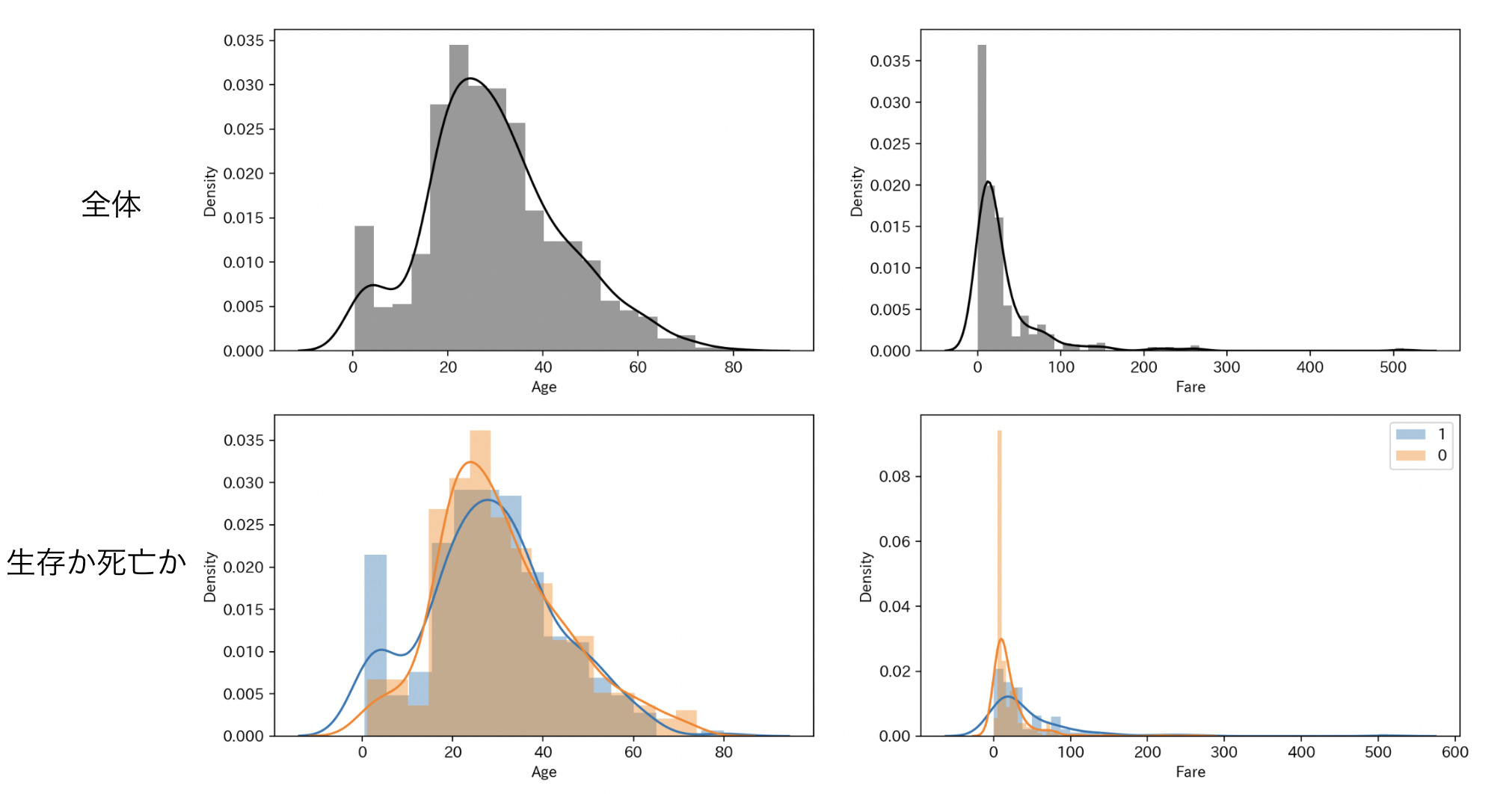
それぞれのカラムの意味をまとめておきます。
- Age – 年齢
- Fare – 料金
得られた結果から次のことがわかりました。
| カラム | 内容 |
|---|---|
| Age | 0~18 歳ぐらいの子供の生存率が目立ちます。子供や女性は優先的に救助されたんでしょう。 |
| Fare | これは棒グラフで見た結果と同じですね。船の運賃を高く払っているほど生存率が高いです。 |
まだ、可視化できていないカラムもありますが、ここまでにしたいと思います。
2. データの加工
データを加工していきます。
欠損値数の確認
データ内に欠損データがどれくらいあるかを確認していきます。
df_train = pd.read_csv("../train.csv") df_test =pd.read_csv('../test.csv') train_num = df_train.isnull().sum()[df_train.isnull().sum()>0] test_num = df_test.isnull().sum()[df_test.isnull().sum()>0] print("---train---") print(train_num) print("---test---") print(test_num) 結果 ---train--- Age 177 Cabin 687 Embarked 2 dtype: int64 ---test--- Age 86 Fare 1 Cabin 327 dtype: int64
Cabin、Age、Embarked、Fare に欠損値を含んでいます。
これらのカラムは削除するか加工する必要がありそうです。
欠損値の補完
欠損値を加工していきます。
欠損値に対する処理ですが、平均値や中央値がよく使われるそうです。
今回は次のような対応でいきたいと思います。
| 項目 | 処理方法 |
|---|---|
| Cabin | 欠損値が多いので削除する。 |
| Age | 平均値を代入する。 |
| Embarked | S の割合が全体的に多いので S を代入する。 |
| Fare | 平均値を代入する。 |
# EmbarkedのSを代入 df_train["Embarked"] = df_train["Embarked"].fillna("S") # Ageの平均値を代入 df_train["Age"] = df_train["Age"].fillna(df_train["Age"].median()) df_test["Age"] = df_test["Age"].fillna(df_test["Age"].median()) # Cabinを削除 df_train = df_train.drop('Cabin',axis='columns') df_test = df_test.drop('Cabin',axis='columns') # Fareの平均値を代入 df_test["Fare"] = df_test["Fare"].fillna(df_test["Fare"].median())
カテゴリカル変数を数値変換
カテゴリカル変数では学習に用いることができないので数値に変えていきます。
カテゴリカル変数は以下のものがありました。
- Name
- Sex
- Embarked
Name は種類が多すぎるので学習には用いません。そのため無視です。
Sex は、男性を 0、女性を 1 にします。
Embarked は、S を 0、C を 1、Q を 2 にします。
# カテゴリカル変数の変換 df_train.replace({'Sex': {'male': 0, 'female': 1}}, inplace=True) df_test.replace({'Sex': {'male': 0, 'female': 1}}, inplace=True) df_train.replace({'Embarked': {'S': 0, 'C': 1, 'Q' : 2}}, inplace=True) df_test.replace({'Embarked': {'S': 0, 'C': 1, 'Q' : 2}}, inplace=True)</code></pre>
加工は以上になります。
特徴量生成
既存の特徴量から新しい特徴量を作っていきたいと思います。
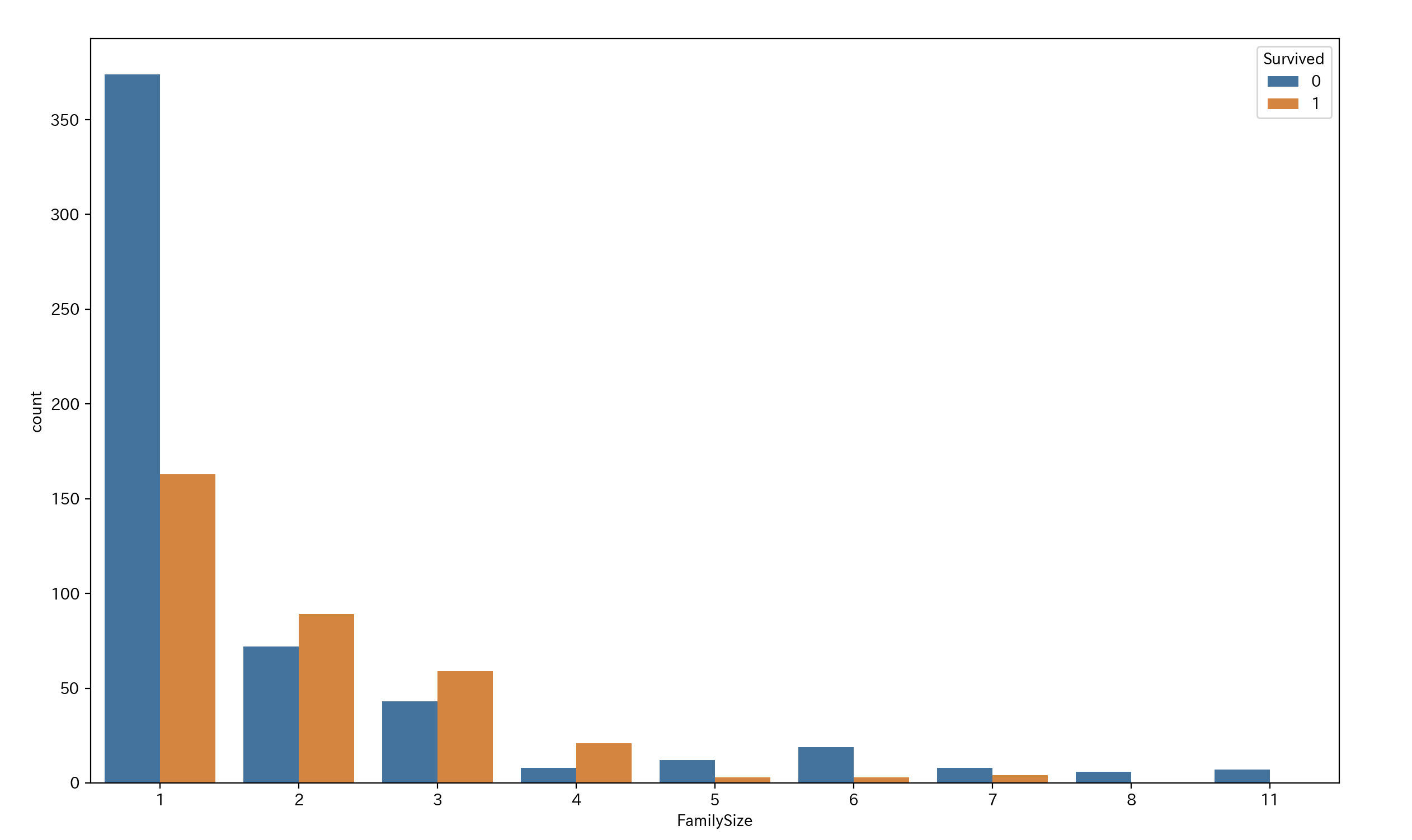
Parch と SibSp を見ると、同乗した親族が多いほど生存率が低いのがわかります。
ですので、Parch と SibSp を組み合わせて FamilySize という新たなカラムを作成します。 コード内の 1 は乗船した本人の数です。
# 1は乗車本人の数 df_train['FamilySize'] = df_train['Parch'] + df_train['SibSp'] + 1 # 分布を確認 sns.countplot(x='FamilySize', data = df_train, hue = 'Survived') plt.show()
相関関係と相互情報量
相関関係の可視化
目的変数(Survived)と相関関係が強いカラムを学習することは、モデルの学習に大きく影響を及ぼします。 そのため、Survived と他のカラムの相関関係を見ていきたいと思います。
今回は、ピアソンの積率相関係数、スピアマンの順位連関係数を用いて相関関係を見ていきたいと思います。 pandas のメソッドを用いることで容易に扱うことができます。
# 相関係数の算出 df_pearson = df_train.corr(method='pearson') df_spearman = df_train.corr(method='spearman') # ヒートマップで可視化 sns.heatmap(df_pearson, annot=True) plt.title('Correlation coefficient (pearson)',fontsize=18) plt.ylim(df_pearson.shape[1],0) plt.show() sns.heatmap(df_spearman, annot=True) plt.title('Correlation coefficient (spearman)',fontsize=18) plt.ylim(df_spearman.shape[1],0) plt.show()
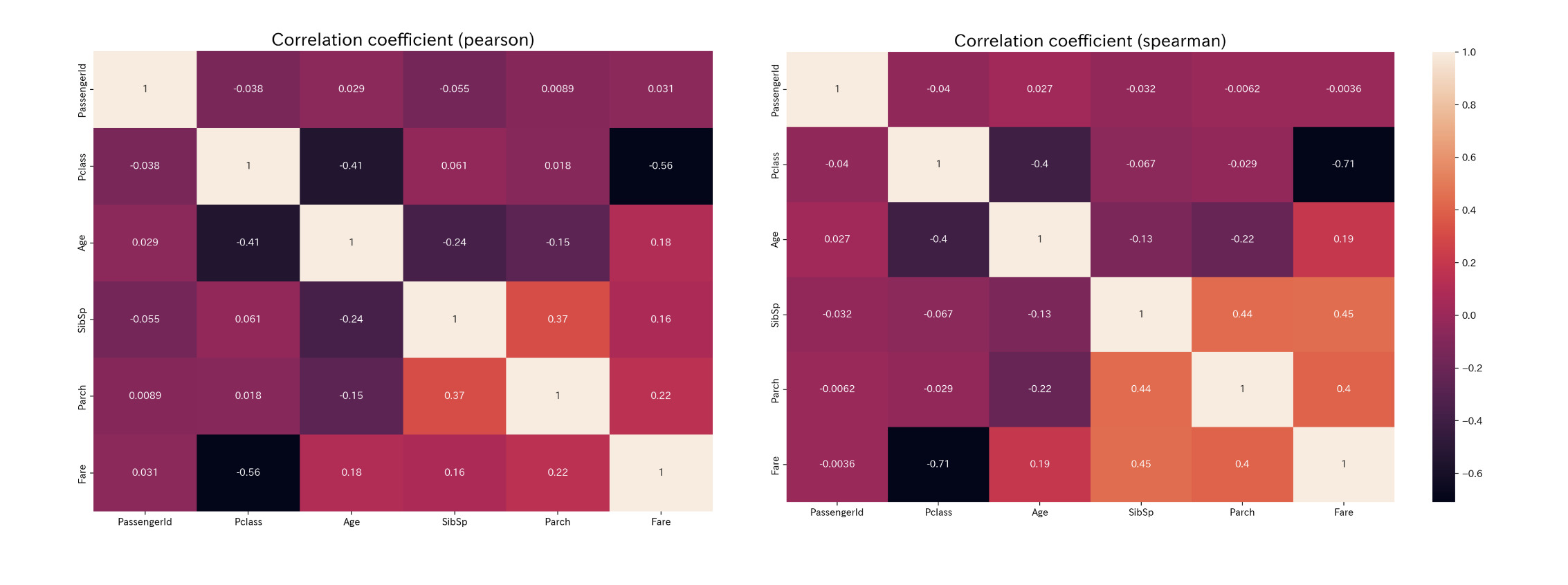
値が大きいものに着目してまとめると
- Survived : Fare とは正の相関関係、Pclass とは負の相関関係がある。
- Pclass : Survived、Age、Fare と負の相関関係がある。
- Age : Pclass、SibSp、Parch と負の相関関係がある。
- SibSp : Age と負の相関関係、Parch、Fare と正の相関関係がある。
- Parch : SibSp、Fare と相関関係がある。
- Fare : Pclass と負の相関関係、Survived、Parch と正の相関関係がある。
相関係数はカラム間の線形関係がわかるのですが、何だか物足りない気がしますね。
本当は相互情報量を見て、Survived との関連性を見るのがいいのですが、今回はやめておきます。
学習
モデルの学習を行います。
今回は、ランダムフォレストというものを使っていきたいと思います。sklearn から引っ張ってきます。(sklearn のランダムフォレスト)
import from sklearn.ensemble import RandomForestClassifier as rfc def random_forest(train_data, test_data, purpose_variable, explanatory_variable): #modelを構築 rc = rfc(random_state=100) # 目的変数の値を取得 target = train_data[purpose_variable].values # 説明変数の値を取得 train_features = train_data[explanatory_variable].values #modelを学習 rc.fit(train_features, target) # 説明変数の値を取得(test) test_features = test_data[explanatory_variable].values # 学習したモデルで分類 predict = rc.predict(test_features) return predict # 目的変数 purpose_variable = ["Survived"] # 説明変数 explanatory_variable = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked", "FamilySize"] # 学習 pridict = random_forest(df_train, df_test, purpose_variable, explanatory_variable)
学習結果を提出
予測できた結果と生存者 ID を結合して CSV ファイルに変換します。
def change_submit_file(id_name, predict_id_name, test, predict): id_name = str(id_name) predict_id_name = str(predict_id_name) submit = pd.DataFrame({id_name: test[id_name], predict_id_name: predict}) submit.to_csv("submit.csv", header=True, index=False) print("Your submission was successfully saved!") change_submit_file("PassengerId", "Survived", df_test, pridict)
保存された CSV ファイルを提出すれば終わりです。
結果は........Score: 0.74880
まぁ、ざっくりやったのでこんなものと言い訳します。
最後に
ここまで読んでいただきありがとうございます。